
IA industrielle & écoingénierie

Temps de lecture : environ 20 minutes
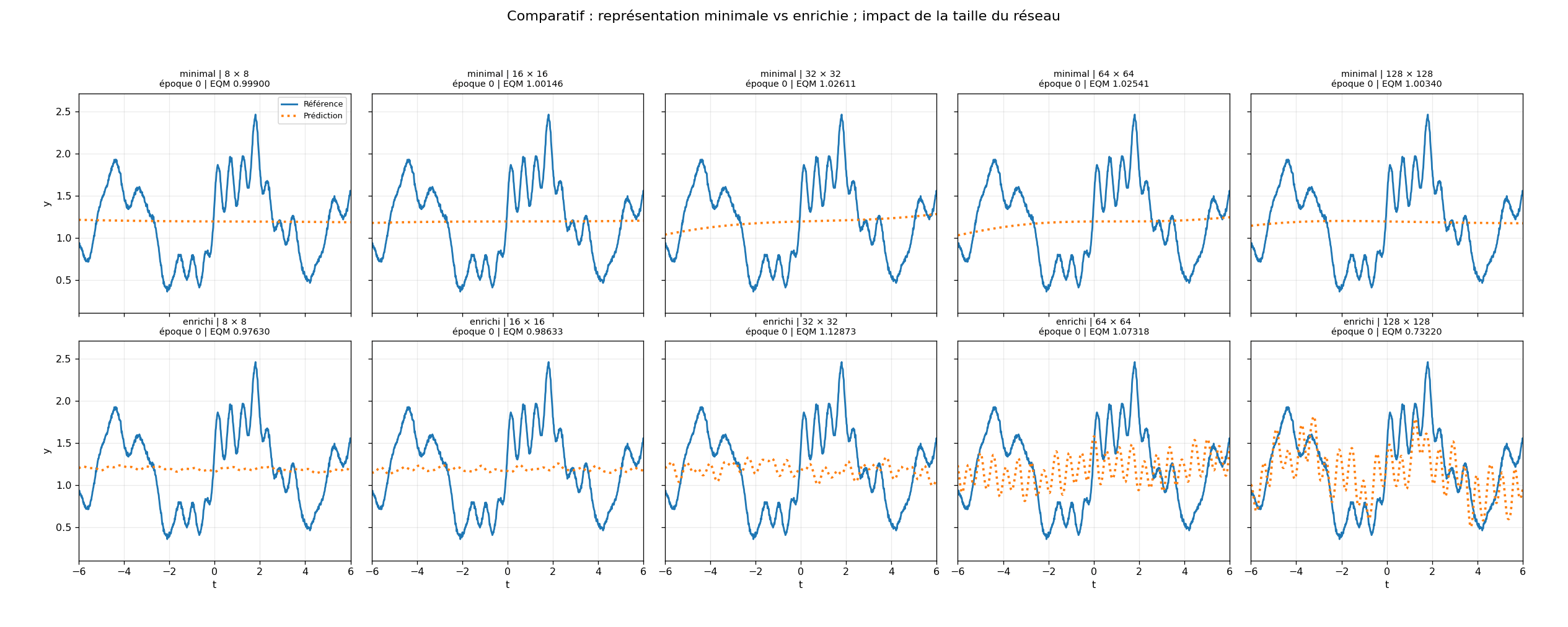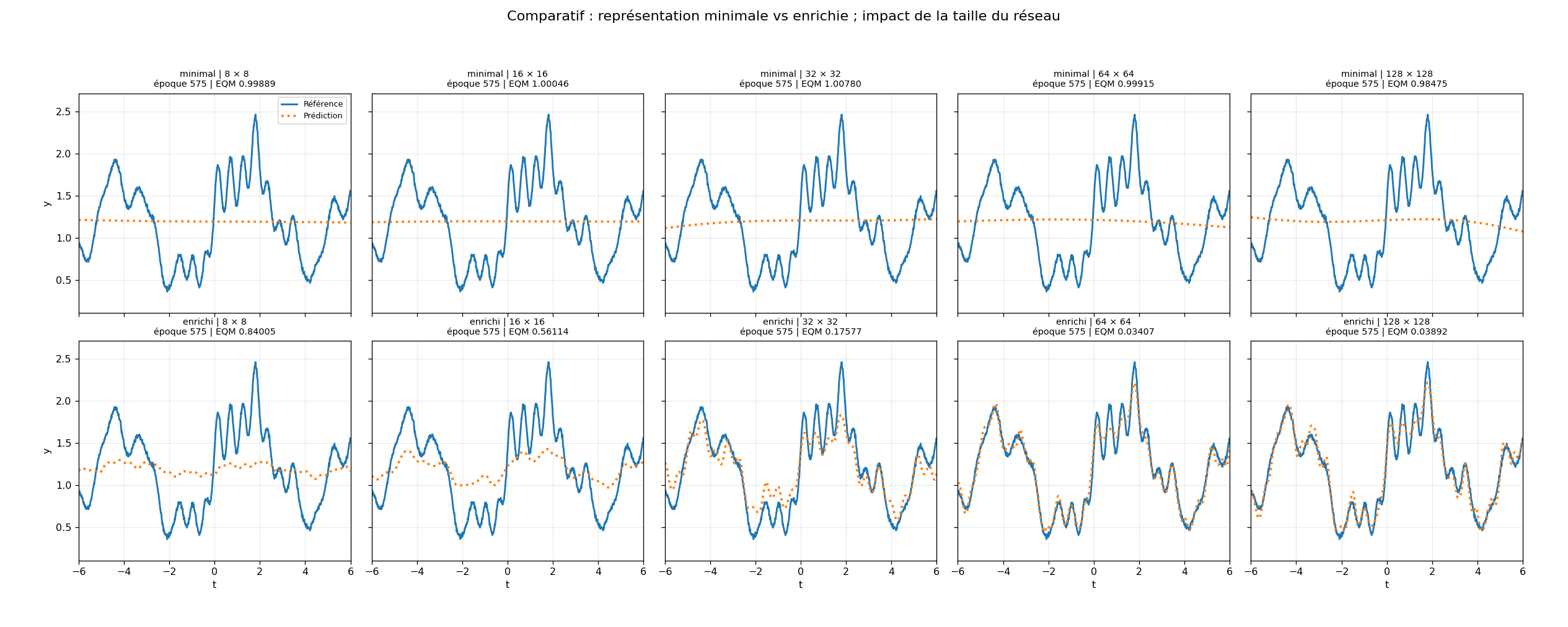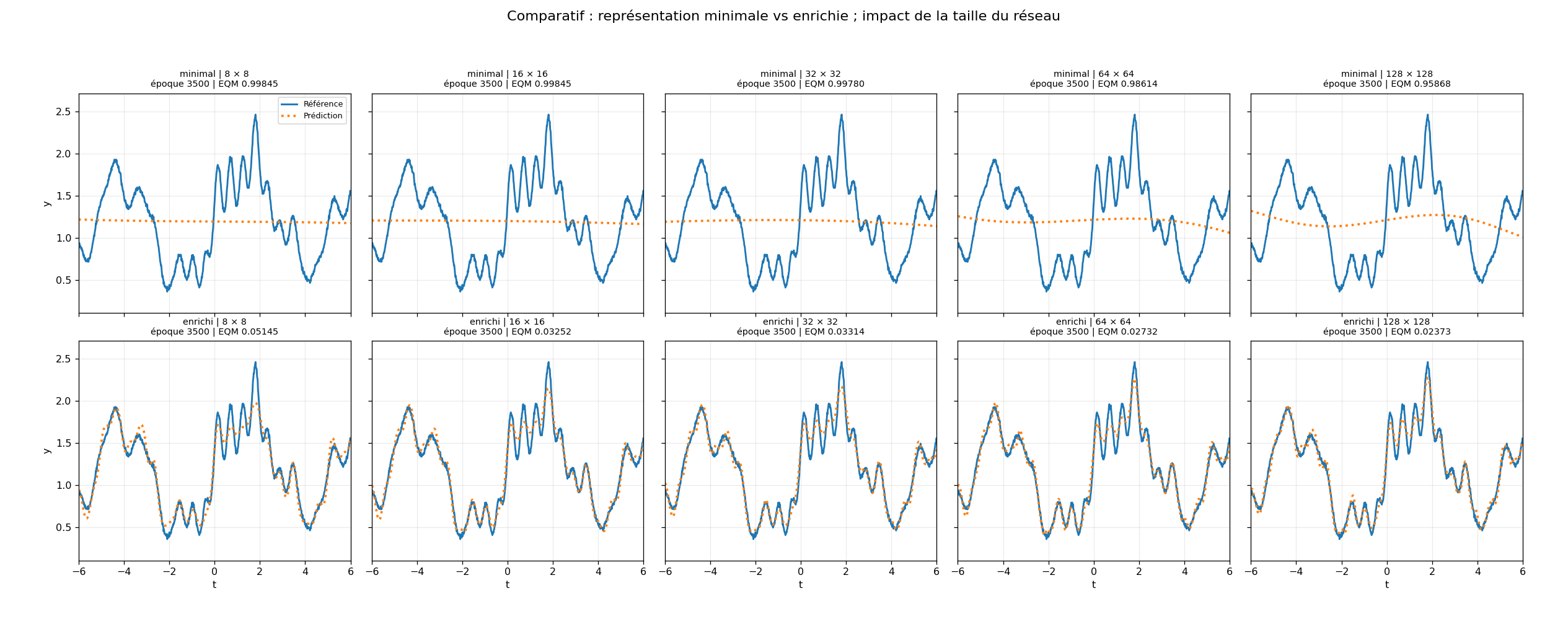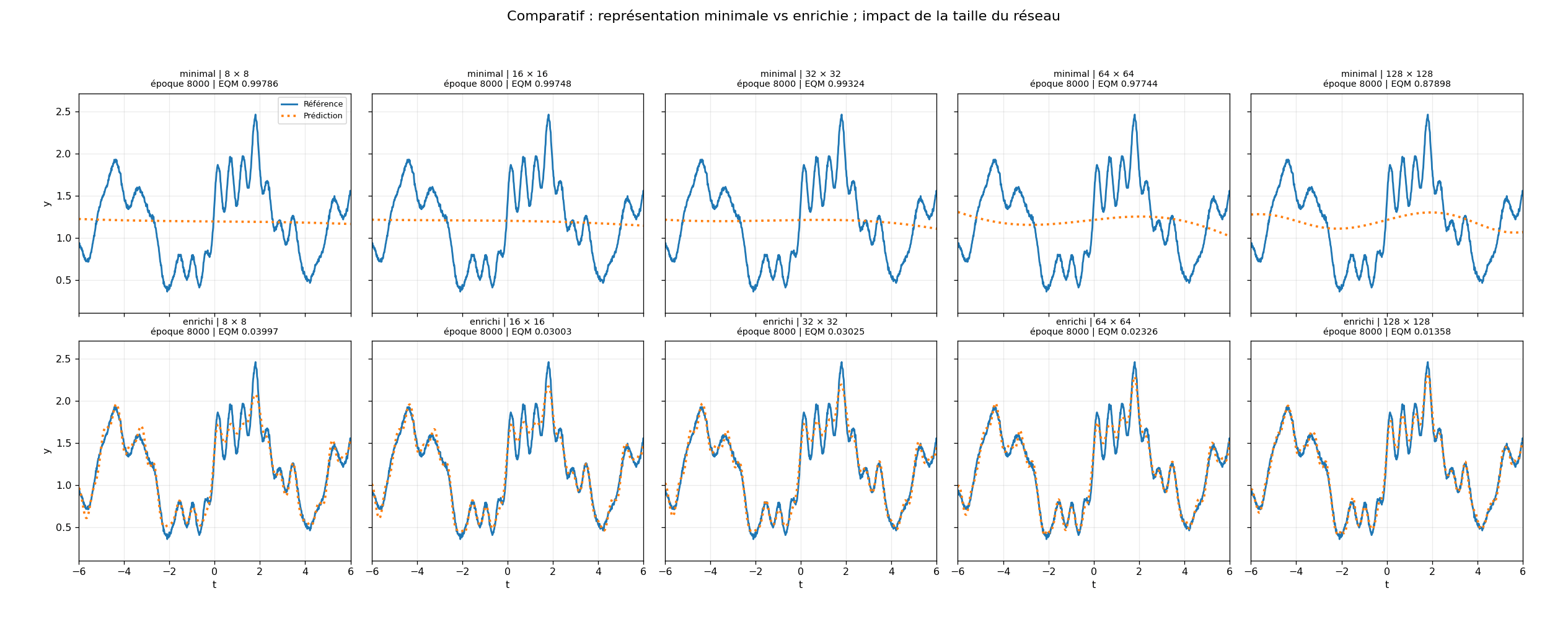
Crédit Photo : Prométhée T&I - Descriptif : Époque 0 : les dix réseaux partent du même point. En haut, le mode minimal : cinq architectures, de la plus petite à la plus grande. En bas, le mode enrichi. Dès les premières époques, la différence n'est pas là où on l'attend : ce n'est pas la taille du réseau qui sépare les courbes. C'est la qualité de ce qu'on lui donne à apprendre.
Cet article propose une démonstration pédagogique rigoureuse d'un sujet fondamental et souvent mal posé en IA industrielle : ce qu'un réseau neuronal apprend réellement lorsqu'il semble apprendre un système complexe. Son ambition : montrer que la performance d'un modèle dépend autant de la représentation des données en entrée que de la taille de l'architecture, illustrer ce que signifie apprendre une référence nominale, et montrer comment un résidu structuré trahit un biais de représentation bien plus qu'une simple erreur numérique.
Car, au-delà des discours sur la puissance des modèles et la promesse de la maintenance prévisionnelle, l'IA industrielle utile commence toujours par une question beaucoup plus sobre : à quoi ressemble le comportement normal d'un système ? Tant que cette question n'a pas de réponse rigoureuse, mesurée et validée, aucun modèle, aussi grand soit-il, ne peut prétendre détecter une dérive ou anticiper une défaillance. Un modèle frugal, bien représenté et bien validé, peut souvent surpasser un modèle plus massif lorsque ce dernier est alimenté par une représentation pauvre, mal contextualisée ou insuffisamment qualifiée.
« Avant de détecter une anomalie, encore faut-il savoir ce que signifie fonctionner normalement. »
⏱️ L'essentiel en 30 secondes
- Un réseau neuronal n'apprend pas « l'intelligence » d'un système ; il apprend une approximation de son comportement sur un domaine observé.
- Avant de détecter une dérive, il faut construire une référence fiable du comportement nominal : c'est le premier étage, souvent négligé, de toute démarche de maintenance conditionnelle ou prévisionnelle.
- La performance dépend autant de la représentation des données que de la taille du modèle : c'est le résultat central de cette démonstration.
- Dans la configuration observée, un petit réseau enrichi (8 × 8 neurones) surpasse un grand réseau minimal (128 × 128) par un facteur 20 sur l'erreur finale.
- Un résidu structuré ne signale pas seulement une erreur numérique : il révèle un biais de représentation, c'est-à-dire une dynamique que le modèle n'a pas réussi à absorber.
- L'enrichissement fréquentiel est un acte d'ingénierie guidé par la connaissance du phénomène, non une recette universelle : il suppose des hypothèses sur la structure du signal et une validation sur des régimes non vus.
- La maintenance prévisionnelle suppose trois étages distincts : apprendre le nominal ; surveiller l'écart au nominal ; relier cet écart à une trajectoire de défaillance et à une criticité opérationnelle.
- L'IA frugale n'est pas une IA au rabais : c'est une IA dimensionnée, validée et proportionnée au réel. Et le réel ne se comprend jamais sans métier, mesure et validation.
Il y a ce que l'on montre de l'IA, et ce que l'on en fait réellement.
Chez Prométhée Technologies & Ingénierie, une part significative de nos interventions porte sur des systèmes instrumentés, des chaînes de production et des environnements où les données sont rares, bruitées, contextualisées par la physique d'un procédé et par la mémoire d'une machine. C'est là que travaillent nos équipes au quotidien. L'article que je vous propose aujourd'hui est construit dans une perspective délibérément pédagogique : vous montrer ce qu'il y a sous le capot, et vous donner, en creux, un aperçu fidèle de ce que nous mettons en œuvre chez nos clients industriels.
C'est peut-être l'une des questions les plus sobres, et pourtant les plus fondamentales, de l'IA industrielle.
Non pas, d'abord : « comment prédire une panne ? » Mais plutôt : à quoi ressemble le comportement nominal d'un système ?
Une machine, un procédé, une armoire électrique, un serveur, un moteur ou un capteur produit des signaux qui varient en permanence. Ces variations ne sont pas nécessairement des anomalies. Elles peuvent traduire la charge, le régime, la température, l'environnement, l'usure normale, un cycle de production ou une condition d'exploitation particulière.
L'enjeu n'est donc pas de promettre une prédiction de panne comme par magie. L'enjeu est plus exigeant, plus discret, mais beaucoup plus fondateur : construire une référence fiable du comportement attendu.
C'est l'un des socles de la surveillance du nominal, de la maintenance conditionnelle et, lorsque l'historique, la physique du système et la validation le permettent, de la maintenance prévisionnelle.
🔧 Sous le capot
Dans une formulation très simple, on peut considérer qu'un modèle apprend une référence nominale, notée ŷ(t), c'est-à-dire une approximation du comportement attendu y(t) sur un domaine observé.
L'écart entre la mesure et la prédiction s'appelle un résidu : r(t) = y(t) - ŷ(t).
Dans un démonstrateur pédagogique, ce résidu mesure d'abord l'erreur du modèle. Dans un contexte industriel, s'il est correctement construit, qualifié et surveillé, il peut aussi devenir un indicateur d'écart au nominal.
Mais cela suppose une condition essentielle : le nominal doit avoir été défini, mesuré, contextualisé et validé avec rigueur.
Dans la démonstration que j'ai construite, le signal cible est volontairement synthétique. Il ne prétend pas représenter une machine réelle. Il combine une dérive lente, des oscillations, des harmoniques et une composante localisée, comme on pourrait en rencontrer dans certains signaux industriels instrumentés.
Le but n'est pas de faire croire qu'un réseau neuronal « comprend » le système. Le but est de montrer comment un modèle peut apprendre une signature nominale, puis jusqu'où il peut la restituer selon deux facteurs : la taille du réseau ; la qualité de la représentation fournie en entrée.
Pour cela, j'ai comparé plusieurs architectures très simples : 8 × 8 neurones ; 16 × 16 ; 32 × 32 ; 64 × 64 ; 128 × 128 neurones.
Pour chaque taille, deux situations ont été testées.
Dans la première, le réseau reçoit une représentation minimale de la variable de régime. Dans la seconde, il reçoit une représentation enrichie, avec des composantes construites, notamment polynomiales et fréquentielles.
L'objectif est volontairement pédagogique : observer ce que change la représentation du problème, à architecture comparable.
Et c'est là que les choses deviennent intéressantes.
Le mode minimal apprend une partie du comportement. Il capte certaines tendances générales, mais peine à restituer les oscillations fines et les structures locales. Le mode enrichi converge beaucoup plus vite et restitue plus fidèlement la signature nominale, parfois avec des réseaux très petits.
Le réseau n'est pas devenu magiquement plus intelligent. Le problème a été mieux représenté.
🔧 Sous le capot
 |
 |
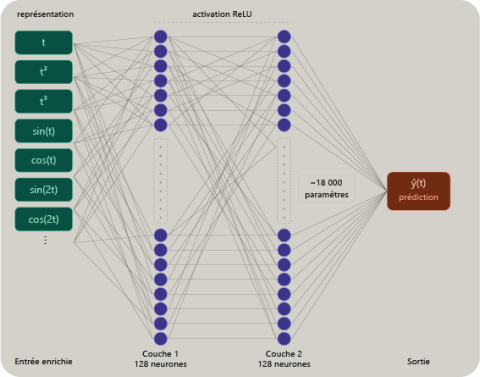
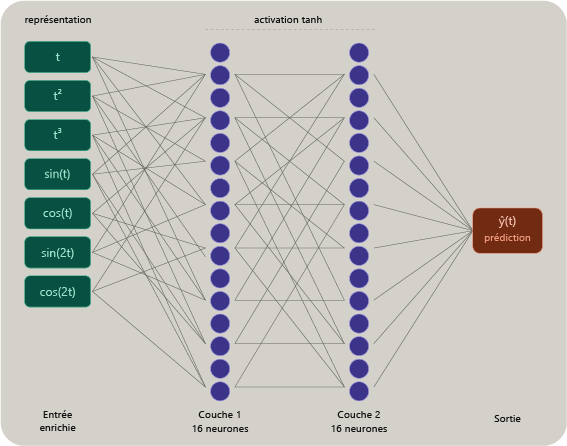
Un réseau neuronal de type « fully connected », ou pleinement connecté, est composé de couches successives de neurones. Dans ce type d'architecture, chaque neurone d'une couche reçoit tous les signaux issus de la couche précédente. Il en calcule une somme pondérée, ajoute éventuellement un biais, puis applique une fonction dite d'activation.
Cette organisation comprend généralement quatre éléments : une couche d'entrée, qui reçoit les variables fournies au modèle ; une ou plusieurs couches cachées, qui transforment progressivement ces informations ; des poids et des biais, qui constituent les paramètres ajustés pendant l'apprentissage ; enfin, une couche de sortie, qui produit la prédiction recherchée.
Dans un réseau neuronal, la fonction d'activation introduit une non linéarité entre deux couches de calcul. Sans elle, empiler plusieurs couches ne changerait pas fondamentalement la nature du modèle : une succession d'opérations linéaires reste linéaire, quel que soit le nombre de couches. C'est cette non linéarité qui permet au réseau d'approximer des relations courbes, des transitions progressives, des seuils ou des structures locales ; autant de formes que l'on rencontre fréquemment dans les signaux industriels.
La ReLU, pour Rectified Linear Unit, est l'une des fonctions d'activation les plus connues. Elle s'écrit :
f(x) = max(0, x)
Si le signal entrant est positif, il est transmis tel quel. S'il est négatif, il est ramené à zéro. Sa simplicité en fait une fonction très utilisée dans de nombreuses architectures modernes, notamment dans les réseaux profonds.
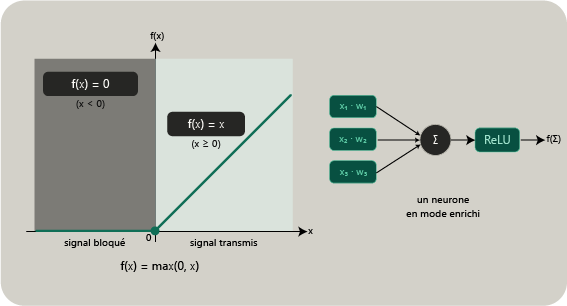
Exemple de fonction d'activation non linéaire : la ReLU. Dans le démonstrateur chiffré présenté ici, la fonction effectivement utilisée n'est pas ReLU, mais tanh ; ReLU est montrée comme repère pédagogique pour illustrer le rôle général d'une activation.
Dans la démonstration présentée ici, la fonction effectivement utilisée est la tangente hyperbolique, notée tanh(x). Elle s'écrit :
f(x) = tanh(x)
Elle transforme toute valeur réelle en une sortie comprise entre -1 et +1, selon une courbe en S symétrique autour de l'origine. Contrairement à ReLU, tanh est bornée et centrée autour de zéro. Ce choix est cohérent avec le démonstrateur, car le signal cible est centré et réduit avant apprentissage.
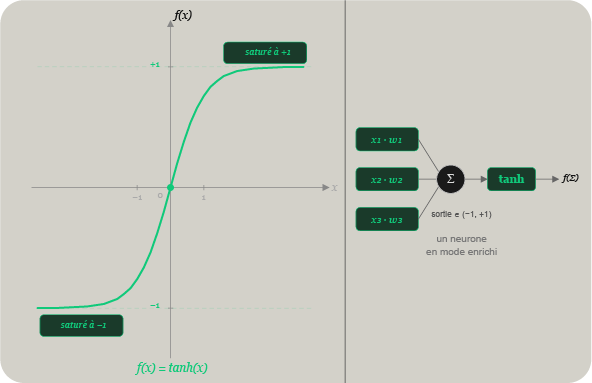
Fonction d'activation effectivement utilisée dans le démonstrateur : tanh. Sa sortie bornée entre -1 et +1 fournit une plage numérique maîtrisée, adaptée au signal normalisé utilisé dans cette expérience.
Ce choix d'activation n'est toutefois pas le coeur de la démonstration. L'écart observé entre les modèles provient d'abord de la qualité de la représentation fournie en entrée, et non de la taille brute du réseau ni du seul choix de la fonction d'activation.
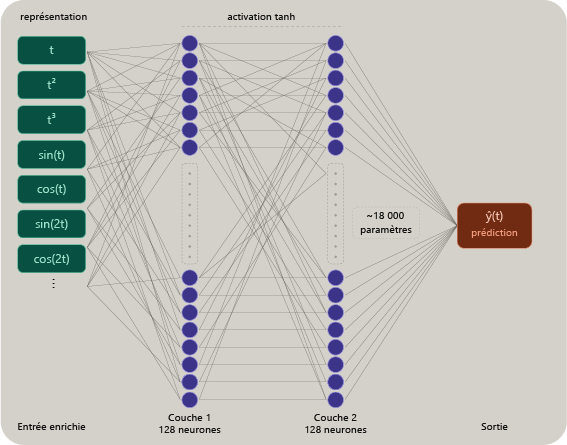
La couche d'entrée reçoit les variables fournies au réseau. Dans le mode minimal, elle contient trois termes : t normalisé, t² normalisé et t³ normalisé. Dans le mode enrichi, elle conserve ces trois composantes et ajoute huit termes sinusoïdaux et cosinusoïdaux correspondant aux fréquences introduites dans le signal synthétique. Les deux familles de modèles conservent la même profondeur, les mêmes tailles de couches cachées et les mêmes paramètres d'entraînement ; seule la représentation d'entrée varie afin d'isoler son effet sur l'apprentissage.
Les couches cachées effectuent la transformation progressive du signal d'entrée vers la sortie. Dans cette démonstration, un réseau 16 × 16 contient deux couches cachées de 16 neurones chacune, soit environ 350 paramètres entraînables en mode minimal et 480 en mode enrichi. Un réseau 128 × 128 en contient environ 17 000 à 18 000 selon la représentation d'entrée. La taille du réseau augmente donc fortement, mais elle ne suffit pas, à elle seule, à compenser une représentation initiale insuffisamment informative.
La sortie produit un scalaire unique : ŷ(t), l'approximation de la signature nominale au point t considéré.
Ce que ce schéma rend immédiatement visible est essentiel : la richesse ou la pauvreté de la couche d'entrée constitue le premier déterminant de ce que le réseau pourra apprendre. Les couches cachées, quelle que soit leur taille, peuvent recombiner, transformer et hiérarchiser l'information fournie ; mais elles ne peuvent compenser durablement l'absence d'une variable physique déterminante, d'un régime non observé ou d'un contexte d'exploitation non représenté.
Dans le mode minimal, le réseau reçoit une information volontairement sobre : une variable de régime normalisée et quelques termes polynomiaux simples. Dans le mode enrichi, il reçoit aussi des variables construites : sinus, cosinus, composantes cohérentes avec la structure fréquentielle du signal.
Cela ne signifie pas que l'on « triche ». Cela illustre un principe fondamental en apprentissage statistique et en ingénierie des systèmes : la performance dépend autant de la représentation des données que de la puissance du modèle.
Un réseau neuronal n'apprend jamais dans le vide. Il apprend à partir d'une représentation du réel. Et cette représentation n'est jamais neutre.
Les chiffres obtenus sur cette démonstration sont très parlants.
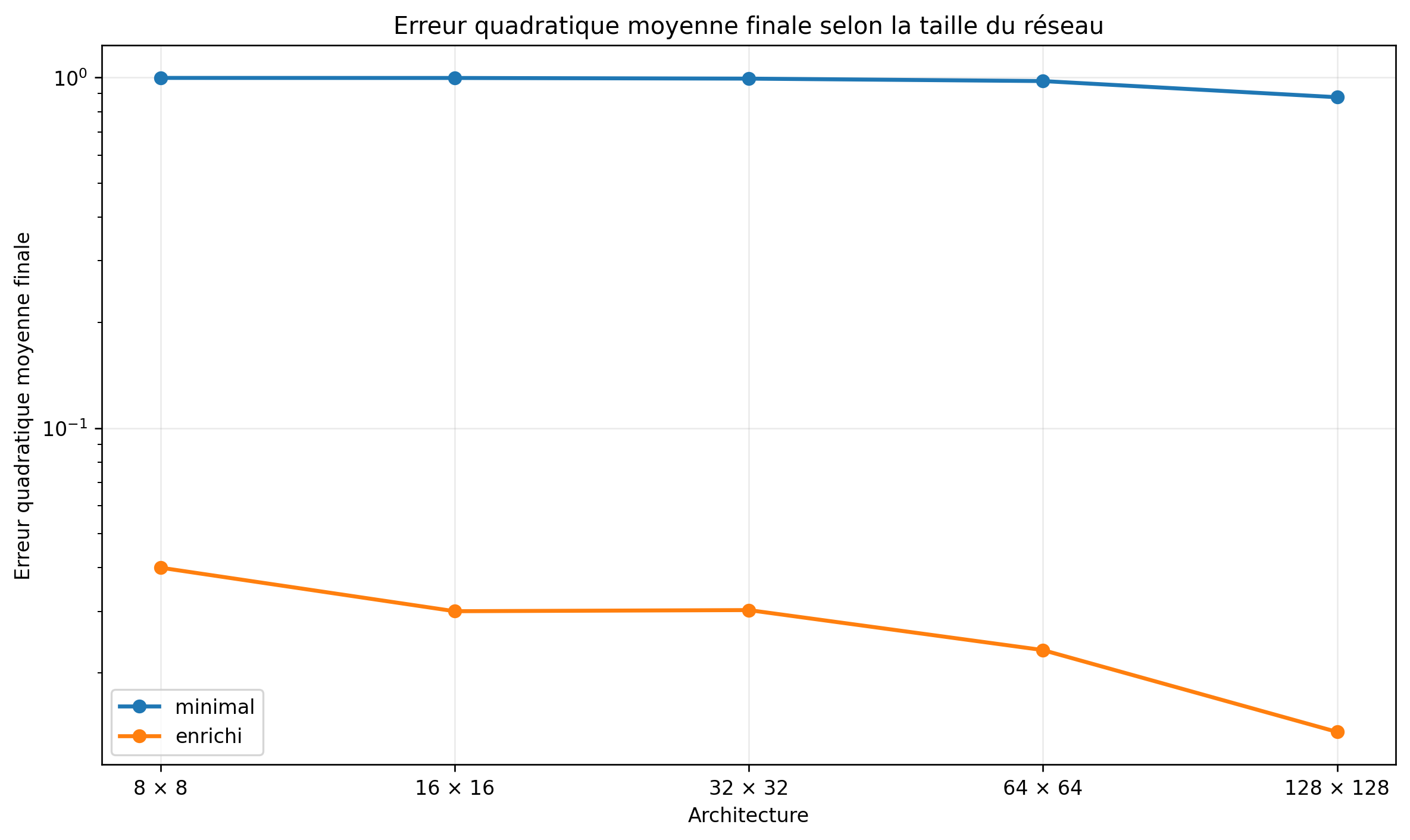
À architecture égale, l'écart entre les deux modes n'est pas marginal. Dans la configuration observée, à 128 × 128 neurones, le mode enrichi atteint une erreur environ 50 à 60 fois plus faible que le mode minimal. Plus frappant encore : un petit réseau enrichi de 8 × 8 neurones surpasse le réseau minimal de 128 × 128 neurones, avec un écart de l'ordre d'un facteur 20 sur l'erreur finale.
Conditions de calcul de la démonstration
Cette démonstration repose sur un signal synthétique contrôlé, combinant dérive lente, oscillations, harmoniques, résonance locale et bruit faible. Les réseaux comparés possèdent deux couches cachées pleinement connectées, avec activation tanh, et une sortie scalaire.
Les architectures testées sont 8 × 8, 16 × 16, 32 × 32, 64 × 64 et 128 × 128 neurones. L'apprentissage est conduit pendant 8 000 époques, par descente de gradient explicite, avec un taux d'apprentissage fixé à 0,0015. La fonction de perte est l'erreur quadratique moyenne, calculée sur le signal cible centré et réduit.
Le mode minimal reçoit trois variables d'entrée : t, t² et t³, après normalisation de l'échelle temporelle. Le mode enrichi ajoute des composantes sinusoïdales et cosinusoïdales correspondant aux fréquences présentes dans le signal synthétique. La graine aléatoire est fixée à 42 afin de rendre l'expérience reproductible.
Il ne s'agit pas d'une validation industrielle sur données non vues, mais d'une comparaison pédagogique à protocole contrôlé. Elle illustre un principe : à architecture comparable, une représentation physiquement mieux informée peut fortement améliorer la convergence et la qualité d'approximation.
Ce n'est pas un gain cosmétique. C'est un changement de régime.
Et ce résultat porte un message très simple : ajouter des neurones ne compense pas une représentation insuffisante du problème. À l'inverse, une représentation pertinente peut permettre à un modèle très modeste de produire une approximation fidèle sur le domaine étudié.
Mais il y a un second enseignement, moins visible dans une simple courbe d'erreur, et pourtant tout aussi important : la nature des résidus.
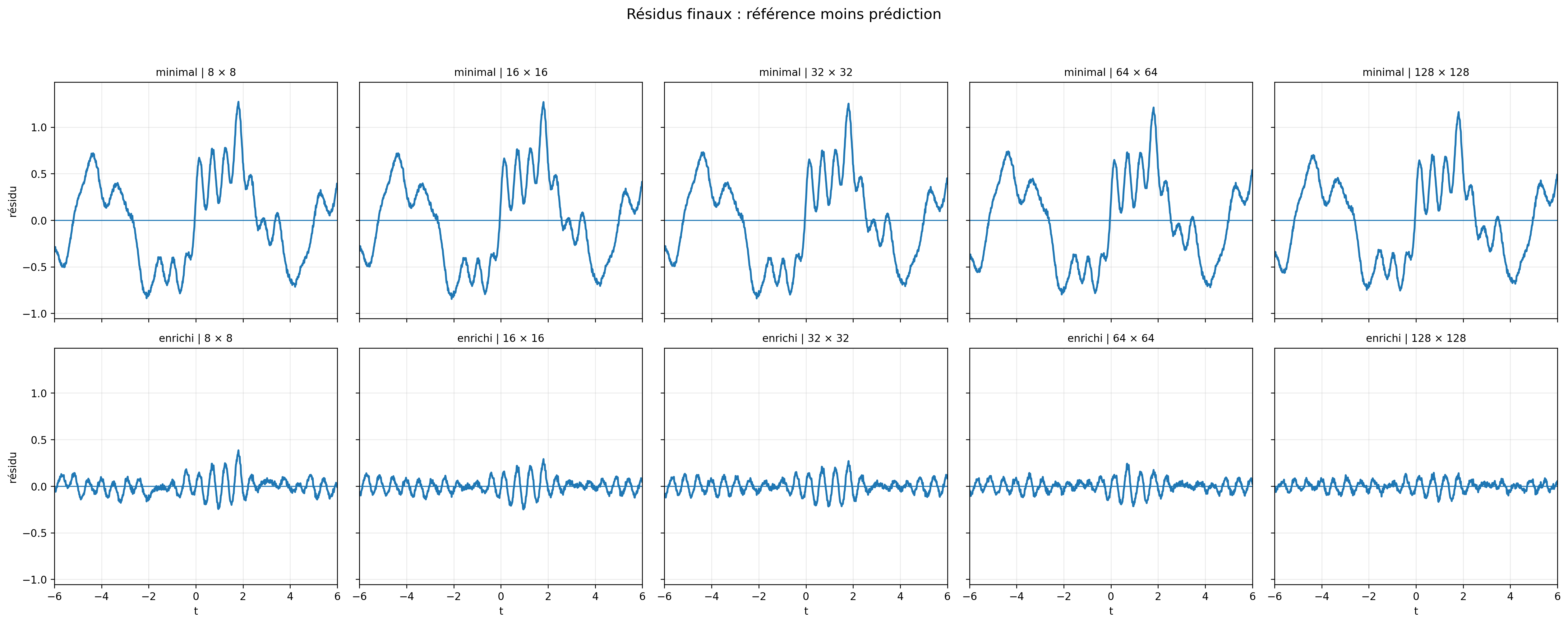
Dans le mode minimal, les résidus ne sont pas seulement plus grands. Ils restent structurés. On y observe des oscillations cohérentes, des motifs persistants, une organisation qui suit encore la dynamique du signal. Ce n'est pas seulement de l'erreur. C'est un biais de représentation : le modèle a appris une partie de la tendance, mais n'a pas absorbé la structure complète du phénomène.
Dans le mode enrichi, les résidus deviennent beaucoup plus faibles et nettement moins structurés. Visuellement, ils se rapprochent d'un résidu centré de nature bruitée (ce qui suggère que le modèle a mieux capté la régularité utile du signal). Pour être rigoureux, cette observation visuelle mériterait d'être complétée par des indicateurs statistiques : autocorrélation ; distribution ; stabilité par sous-domaines. La courbe oriente l'analyse. La validation la clôt.
Cette distinction est pourtant essentielle dès la lecture visuelle.
Un résidu structuré indique souvent que quelque chose reste à apprendre : une variable absente ; un régime mal représenté ; une dynamique négligée ; un effet physique non modélisé. Un résidu faible et peu structuré indique, au contraire, que le modèle a probablement capté l'essentiel de la régularité disponible dans le périmètre observé.
🔧 Sous le capot
En traitement du signal industriel, l'équivalent concret d'une représentation enrichie peut prendre de nombreuses formes : une énergie par bande fréquentielle ; une dérivée temporelle ; une moyenne glissante ; un indicateur de régime ; une température corrigée de la charge ; une signature vibratoire contextualisée ; un état de cycle machine ; un historique court ; une grandeur physique reconstruite à partir de plusieurs capteurs ; une consigne ; un état d'automate ; une phase de production.
Une bonne variable ne se contente pas d'alimenter un modèle. Elle structure ce qu'il pourra apprendre.
L'IA industrielle ne commence donc pas avec l'algorithme. Elle commence avec la mesure, le cadrage, le choix des variables, la compréhension des régimes et la formulation du problème.
Il faut cependant nommer une nuance importante.
Lorsque l'enrichissement est construit à partir de composantes fréquentielles cohérentes avec la structure connue du signal, on fait du feature engineering guidé par la connaissance du phénomène. C'est une force considérable. Mais c'est aussi une hypothèse implicite sur la forme du signal.
En production, si le régime change, si la machine évolue, si la fréquence de cycle se décale ou si un capteur dérive, ces variables construites peuvent devenir moins pertinentes (voire un biais, précisément parce qu'elles étaient très adaptées au domaine d'entraînement).
La frugalité peut donc avoir un coût de généralisation si elle repose sur des hypothèses trop étroites. C'est pourquoi l'enrichissement de la représentation n'est pas une recette universelle. C'est un acte d'ingénierie, qui suppose une connaissance du système, une hypothèse sur sa structure et une discipline de validation sur des régimes non vus.
🔧 Sous le capot
Ce point rejoint une distinction importante entre trois notions souvent confondues.
Interpoler, c'est bien se comporter dans le domaine déjà couvert par les données. Extrapoler, c'est produire une estimation au-delà de ce domaine. Généraliser, c'est rester pertinent face à des situations nouvelles, mais compatibles avec les hypothèses du modèle.
Un modèle peut être excellent en interpolation et médiocre en extrapolation. Il peut aussi être très performant sur un régime machine et fragile sur un autre.
C'est pourquoi un modèle industriel ne se juge pas seulement sur une erreur finale globale. Il se juge par domaine, par régime, par contexte, par période et par usage opérationnel.
Cette démonstration rappelle donc une idée simple, mais souvent négligée : la taille du modèle n'est pas le seul levier de performance.
On peut augmenter le nombre de neurones, élargir les couches, complexifier l'architecture. Mais si les données d'entrée sont pauvres, mal représentées ou mal contextualisées, le modèle risque surtout d'apprendre difficilement, lentement, ou de manière peu fiable.
La question n'est pas toujours : quel est le modèle le plus puissant ? Elle est souvent : quel est le modèle suffisant, robuste, maintenable, explicable et proportionné au problème réel ?
Cette question relève pleinement d'une logique d'éco-ingénierie. Non pas faire moins bien avec moins. Mais faire juste, avec le bon niveau de complexité. Éviter la surenchère computationnelle ; réduire les besoins de calcul ; faciliter la maintenance ; améliorer la lisibilité opérationnelle ; adapter le système technique au besoin réel plutôt que compenser une mauvaise formulation par un modèle toujours plus gros.
🔧 Sous le capot
Dans cette démonstration, les architectures restent très modestes. Un réseau 128 × 128 avec deux couches cachées représente environ 17 000 à 18 000 paramètres selon la représentation d'entrée (minuscule au regard des modèles massifs contemporains). Un réseau 8 × 8 en contient moins de 400. L'écart entre les deux est d'un facteur 90 en nombre de paramètres, ceci pour des résultats en mode enrichi qui, eux, ne varient que d'un facteur 3 environ sur l'erreur finale.
| Cas | Nombre d'entrées | Calcul | Paramètres |
| Mode minimal | 3 | 3×128 + 128 + 128×128 + 128 + 128×1 + 1 | 17 153 |
| Mode enrichi | 11 | 11×128 + 128 + 128×128 + 128 + 128×1 + 1 | 18 177 |
C'est là que se niche l'un des enseignements les plus nets de cette expérience : le rendement marginal des paramètres supplémentaires s'effondre dès lors que la représentation est déjà bonne. Ajouter de la puissance à un problème bien formulé apporte peu. Formuler correctement un problème qu'un petit modèle ne parvenait pas à résoudre change tout.
La frugalité ne vient donc pas seulement de la réduction du modèle. Elle vient de l'adéquation entre quatre éléments : le phénomène observé ; les données disponibles ; la représentation choisie ; l'usage visé.
Un modèle sobre n'est pas un modèle appauvri. C'est un modèle dimensionné. Et dimensionner, en ingénierie, ce n'est pas réduire aveuglément. C'est ajuster.
Il faut toutefois rester prudent.
Approximer fidèlement une signature nominale sur un domaine observé ne signifie pas comprendre la physique complète du système. Cela ne signifie pas non plus extrapoler correctement hors du domaine d'entraînement.
C'est pourquoi la démonstration ne doit pas être interprétée comme une promesse automatique de maintenance prévisionnelle.
Elle illustre un premier étage : apprendre le nominal. Puis un deuxième : surveiller l'écart au nominal.
La maintenance prévisionnelle, au sens strict, suppose un étage supplémentaire : relier les écarts observés à une trajectoire future, à un risque de défaillance, à une criticité opérationnelle ou à une durée résiduelle avant défaut. C'est un autre niveau d'exigence ; et c'est souvent là que se joue la différence entre une démonstration convaincante et un dispositif industriel fiable.
🔧 Sous le capot
La robustesse d'un modèle industriel ne se décrète pas à partir d'une belle courbe. Elle se teste.
Il faut des données non vues, des régimes distincts, des conditions d'exploitation variées, des perturbations réalistes, une analyse des faux positifs et des faux négatifs, une qualification des seuils d'alerte, une surveillance de la dérive de distribution et une confrontation aux connaissances métier.
Il faut aussi distinguer plusieurs phénomènes qui peuvent se ressembler dans les données : le bruit normal ; la variabilité admissible ; un changement de régime légitime ; une dérive lente ; une anomalie ponctuelle ; un défaut naissant ; un défaut réellement critique.
Sans cette discipline : la donnée peut être exacte et l'interprétation fausse. Le modèle peut être précis et la décision mauvaise. L'alerte peut être statistiquement visible et industriellement insignifiante.
C'est pour cela que l'IA industrielle exige une articulation entre mesure, modèle, métier et décision.
Une IA située, instrumentée, validée : c'est là que commence le vrai travail.
Le message de cette démonstration est donc volontairement sobre.
Un réseau neuronal peut approximer un comportement complexe. Mais ce qu'il apprend dépend fortement de ce qu'on lui donne à apprendre (du signal, du domaine, de la normalisation, de l'architecture, et surtout de la représentation du problème).
En industrie, l'intelligence ne réside donc pas uniquement dans le modèle. Elle réside aussi dans l'instrumentation ; dans la qualité de la mesure ; dans la compréhension du système ; dans le choix des variables ; dans l'analyse des résidus ; dans la discipline de validation ; dans la capacité à relier un résultat numérique à une décision opérationnelle utile.
La démonstration devient alors moins une histoire d'IA spectaculaire qu'une histoire d'ingénierie.
Un petit réseau, bien dimensionné, bien alimenté et bien validé, peut déjà produire des résultats remarquables sur un périmètre clairement défini. À l'inverse, un modèle massif appliqué à des données pauvres ou mal cadrées risque surtout d'apprendre très vite des choses peu fiables.
Ce type de démonstration rappelle qu'un modèle apprend toujours dans un périmètre, à partir d'une représentation donnée, sous des hypothèses qu'il faut connaître.
Et c'est précisément là que commence l'ingénierie. Non pas dans la fascination pour la taille du modèle. Mais dans la rigueur avec laquelle on pose le problème, on mesure le réel, on représente les données, on analyse les résidus, on valide les résultats et on décide jusqu'où l'on peut faire confiance à ce que l'on voit.
Et le réel ne se comprend jamais sans métier, mesure et validation.
Pour Prométhée T&I, ce type de démonstration n'est pas une fin en soi. C'est un point de départ : qualifier le nominal, comprendre les régimes, instrumenter avec discernement, modéliser sans surenchère, puis relier les écarts observés à des décisions opérationnelles utiles. C'est dans cette articulation entre mesure, modèle, métier et décision que l'IA industrielle devient réellement productive.